















Googleスプレッドシートでデータを扱っていると、
- 「特定の条件に合う行だけ表示したい」
- 「必要な列だけ取り出したい」
- 「売上順に並び替えたい」
- 「担当者別に合計したい」
という場面がよくあります。
そんなときに便利なのが、QUERY 関数です。
QUERY 関数を使うと、表の中から必要なデータだけを取り出したり、条件で絞り込んだり、並び替えたり、集計したりできます。
少しだけSQLのような書き方をしますが、基本の形を覚えれば、かなり実務で使いやすい関数です。
QUERY関数の基本形
QUERY 関数の基本形は次のとおりです。
=QUERY(範囲, "クエリ文", 見出し行数)たとえば、次のように使います。
=QUERY(A1:D100, "select A, B where C = '東京'", 1)これは、A1:D100 の範囲から、C列が「東京」の行だけを抽出し、A列とB列だけを表示する式です。
それぞれの意味は次のとおりです。
| 引数 | 内容 |
|---|---|
| 範囲 | 対象にする表の範囲 |
| クエリ文 | どの列を表示するか、どんな条件で絞るかを書く部分 |
| 見出し行数 | 見出しが何行あるか。通常は 1 |
見出しが1行ある表なら、最後の引数は基本的に 1 で問題ありません。
サンプルの表
この記事では、次のような売上表を例にして説明します。
| A列:日付 | B列:担当者 | C列:地域 | D列:売上 |
|---|---|---|---|
| 2026/5/1 | 田中 | 東京 | 12000 |
| 2026/5/2 | 佐藤 | 大阪 | 8000 |
| 2026/5/3 | 田中 | 東京 | 15000 |
| 2026/5/4 | 鈴木 | 名古屋 | 10000 |
| 2026/5/5 | 佐藤 | 東京 | 18000 |
この表が A1:D に入っているものとして進めます。
必要な列だけ取り出す:select
QUERY 関数で最初に覚えたいのが select です。
select は、表示したい列を指定する命令です。
=QUERY(A1:D, "select A, B, D", 1)この式では、A列、B列、D列だけを表示します。
つまり、元の表から「日付」「担当者」「売上」だけを取り出す形です。
すべての列を表示したい場合は、次のように書きます。
=QUERY(A1:D, "select *", 1)* は「すべての列」という意味です。
まずは、
select *と
select A, B, Dの違いを押さえるとわかりやすいです。
条件に合う行だけ取り出す:where
次に重要なのが where です。
where は、条件に合う行だけを表示するために使います。
たとえば、地域が「東京」の行だけを抽出したい場合は、次のように書きます。
=QUERY(A1:D, "select * where C = '東京'", 1)C列が「東京」の行だけが表示されます。
文字列を条件にするときは、必ずシングルクォート ‘ ‘ で囲みます。
where C = '東京'数値を条件にするときは、シングルクォートは不要です。
売上が10,000以上の行だけを表示するなら、次のようになります。
=QUERY(A1:D, "select * where D >= 10000", 1)文字列はクォートあり、数値はクォートなし。
ここは最初につまずきやすいポイントです。
空白行を除外する
実務でとてもよく使うのが、空白行を除外する書き方です。
=QUERY(A1:D, "select * where A is not null", 1)これは、A列が空白ではない行だけを表示する式です。
スプレッドシートでは、範囲を A1:D のように列全体で指定することが多いです。
そのままだと空白行まで対象になることがあるため、次のように書いておくと扱いやすくなります。
where A is not null反対に、空白の行だけを取り出したい場合は、
where A is nullと書きます。
並び替える:order by
データを並び替えたいときは order by を使います。
売上の高い順に並び替えるなら、次のように書きます。
=QUERY(A1:D, "select * where A is not null order by D desc", 1)desc は降順です。
売上が高い順、日付が新しい順などに使います。
反対に、昇順にしたい場合は asc を使います。
=QUERY(A1:D, "select * where A is not null order by D asc", 1)asc は小さい順・古い順、desc は大きい順・新しい順と覚えるとよいです。
件数を制限する:limit
上位何件だけ表示したい、という場合は limit を使います。
売上が高い順に上位3件だけ表示するなら、次のように書きます。
=QUERY(A1:D, "select * where A is not null order by D desc limit 3", 1)このように、order by と limit はセットで使うことが多いです。
たとえば、
order by D desc limit 5と書けば、D列の値が大きい順に並べて、上位5件だけ表示できます。
ランキング表を作るときに便利です。
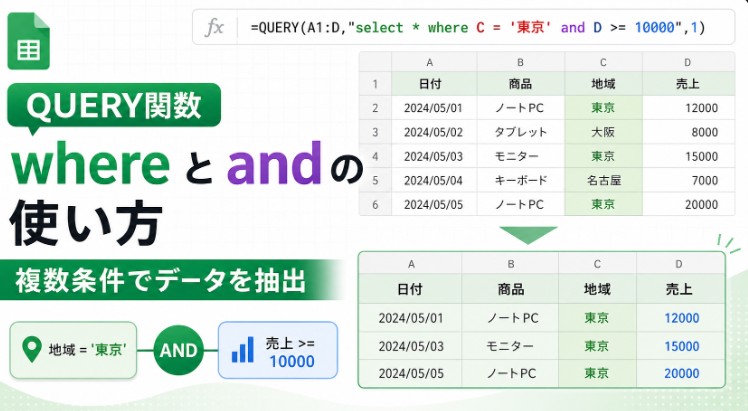
複数条件で絞り込む:and / or
条件を複数指定したい場合は、and や or を使います。
たとえば、地域が東京で、売上が10,000以上の行だけを表示したい場合は次のように書きます。
=QUERY(A1:D, "select * where C = '東京' and D >= 10000", 1)and は「両方の条件を満たす」という意味です。
一方、東京または大阪の行を表示したい場合は or を使います。
=QUERY(A1:D, "select * where C = '東京' or C = '大阪'", 1)条件が複雑になる場合は、括弧を使うとわかりやすくなります。
=QUERY(A1:D, "select * where (C = '東京' or C = '大阪') and D >= 10000", 1)これは、地域が東京または大阪で、かつ売上が10,000以上の行を表示する式です。
文字を含む条件:contains
一部の文字を含むデータを探したい場合は contains を使います。
たとえば、担当者名に「田」を含む行を抽出する場合は、次のように書きます。
=QUERY(A1:D, "select * where B contains '田'", 1)「田中」や「山田」などが該当します。
また、先頭一致なら starts with、末尾一致なら ends with を使います。
=QUERY(A1:D, "select * where B starts with '田'", 1)=QUERY(A1:D, "select * where B ends with '中'", 1)名前、商品名、カテゴリ名などを検索するときに便利です。
集計する:group by
QUERY 関数は、条件抽出だけでなく集計もできます。
たとえば、担当者ごとの売上合計を出したい場合は、次のように書きます。
=QUERY(A1:D, "select B, sum(D) where B is not null group by B", 1)この式では、B列の担当者ごとに、D列の売上を合計しています。
地域ごとの売上合計なら、次のようになります。
=QUERY(A1:D, "select C, sum(D) where C is not null group by C", 1)group by を使うときは、少し注意が必要です。
select に通常の列を指定した場合、その列は group by にも指定する必要があります。
たとえば、これはOKです。
=QUERY(A1:D, "select C, sum(D) group by C", 1)しかし、これはエラーになります。
=QUERY(A1:D, "select B, C, sum(D) group by C", 1)B列を select に入れているのに、group by に入っていないためです。
正しくはこうです。
=QUERY(A1:D, "select B, C, sum(D) group by B, C", 1)group by を使うときは、「集計しない列は全部 group by に入れる」と覚えておくと安全です。
見出し名を変更する:label
集計をすると、見出しが sum 売上 のように少し読みにくくなることがあります。
そんなときは label を使って、見出し名を変更できます。
=QUERY(A1:D, "select C, sum(D) group by C label sum(D) '売上合計'", 1)さらに、C列の見出しも変えるなら次のように書きます。
=QUERY(A1:D, "select C, sum(D) group by C label C '地域', sum(D) '売上合計'", 1)集計表をそのまま資料やダッシュボードに使いたい場合、label まで設定しておくと見やすくなります。
日付条件の書き方
QUERY 関数で日付を扱うときは、少し独特な書き方をします。
たとえば、2026年5月1日以降のデータだけを抽出する場合は、次のように書きます。
=QUERY(A1:D, "select * where A >= date '2026-05-01'", 1)日付は、
date 'YYYY-MM-DD'の形で指定します。
スプレッドシート上では 2026/5/1 と表示されていても、QUERY関数の中では 2026-05-01 の形にする必要があります。
セルに入力した日付を条件にしたい場合は、TEXT 関数と組み合わせます。
たとえば、F1セルに開始日が入っている場合は次のように書きます。
=QUERY(A1:D, "select * where A >= date '"&TEXT(F1, "yyyy-mm-dd")&"'", 1)この式は少し長く見えますが、実務ではかなりよく使います。
セル参照を使って条件を変える
QUERY 関数は、セル参照と組み合わせると一気に便利になります。
たとえば、F1セルに地域名を入力し、その地域のデータだけを表示したい場合は、次のように書きます。
=QUERY(A1:D, "select * where C = '"&F1&"'", 1)F1に「東京」と入力すれば東京だけ、F1に「大阪」と入力すれば大阪だけ表示されます。
売上の下限をF1セルで指定する場合は、次のようになります。
=QUERY(A1:D, "select * where D >= "&F1, 1)文字列をセル参照する場合は、前後にシングルクォートが必要です。
"where C = '"&F1&"'"数値をセル参照する場合は、シングルクォートは不要です。
"where D >= "&F1この違いを覚えると、検索フォームのようなシートを作れるようになります。
配列を使う場合は Col1, Col2 形式になる
通常の範囲指定では、列を A, B, C のように指定します。
=QUERY(A1:D, "select A, B, D", 1)しかし、{} を使って配列を作った場合は、列指定が Col1, Col2, Col3 の形式になります。
=QUERY({A1:D}, "select Col1, Col2, Col4", 1)複数の表を縦に結合する場合も同じです。
=QUERY({A1:D; F1:I}, "select Col1, Col2, Col4 where Col3 = '東京'", 1)この違いは、エラーの原因になりやすいです。
通常範囲なら A, B, C。
配列なら Col1, Col2, Col3。
ここはセットで覚えておきましょう。
よく使うQUERY関数のテンプレート
ここからは、実務で使いやすいテンプレートをまとめます。
空白行を除外して表示する
=QUERY(A1:D, "select * where A is not null", 1)特定の地域だけ抽出する
=QUERY(A1:D, "select * where C = '東京'", 1)売上が10,000以上の行だけ抽出する
=QUERY(A1:D, "select * where D >= 10000", 1)売上の高い順に並び替える
=QUERY(A1:D, "select * where A is not null order by D desc", 1)
売上上位5件を表示する
=QUERY(A1:D, "select * where A is not null order by D desc limit 5", 1)
担当者ごとの売上合計を出す
=QUERY(A1:D, "select B, sum(D) where B is not null group by B label sum(D) '売上合計'", 1)地域ごとの平均売上を出す
=QUERY(A1:D, "select C, avg(D) where C is not null group by C label avg(D) '平均売上'", 1)地域ごとの件数を出す
=QUERY(A1:D, "select C, count(C) where C is not null group by C label count(C) '件数'", 1)QUERY関数でよくあるエラー
PARSE_ERROR
PARSE_ERROR は、クエリ文の書き方にミスがあるときに出ます。
特に多いのは、文字列をシングルクォートで囲んでいないケースです。
これはエラーになります。
=QUERY(A1:D, "select * where C = 東京", 1)正しくはこうです。
=QUERY(A1:D, "select * where C = '東京'", 1)NO_COLUMN
NO_COLUMN: A のようなエラーが出る場合は、列指定が合っていない可能性があります。
たとえば、配列 {} を使っているのに A や B で指定しているとエラーになります。
=QUERY({A1:D}, "select A, B", 1)この場合は、次のように Col1, Col2 を使います。
=QUERY({A1:D}, "select Col1, Col2", 1)日付条件で抽出できない
日付条件では、date ‘YYYY-MM-DD’ の形を使います。
=QUERY(A1:D, "select * where A >= date '2026-05-01'", 1)セルの日付を使う場合は、TEXT 関数で形式を整えます。
=QUERY(A1:D, "select * where A >= date '"&TEXT(F1,"yyyy-mm-dd")&"'", 1)QUERY関数を覚える順番
QUERY関数は一度にすべて覚えようとすると、少し難しく感じます。
まずは、次の順番で覚えるのがおすすめです。
- select で列を選ぶ
- where で条件を指定する
- order by で並び替える
- limit で件数を絞る
- group by で集計する
- label で見出しを整える
- セル参照と組み合わせる
- 日付条件を使う
- 配列の Col1 形式を理解する
最初は、次の式を覚えるだけでも十分実用的です。
=QUERY(A1:D, "select * where A is not null", 1)この式をベースに、条件を足したり、並び替えを追加したりしていくと理解しやすくなります。
まとめ
QUERY 関数は、Googleスプレッドシートの中でもかなり強力な関数です。
- 必要な列だけ取り出す。
- 条件に合う行だけ表示する。
- 売上順に並び替える。
- 担当者別や地域別に集計する。
- セル参照と組み合わせて検索表を作る。
こうした処理を、ひとつの関数でまとめて実現できます。
最初はクエリ文の書き方に少し慣れが必要ですが、基本はそれほど複雑ではありません。
まずは、
=QUERY(A1:D, "select * where A is not null", 1)から始めて、少しずつ where、order by、group by を足していくのがおすすめです。
QUERY関数を使えるようになると、スプレッドシートでのデータ整理や集計がかなり楽になります。

